Tenure-track faculty (W2)
Max Planck Institute for Software Systems
Email: mtoneva [at] mpi-sws [dot] org
Office: Room 438 in E1.5, Saarbrücken, Germany
Curriculum Vitae
Google Scholar
X/Twitter
Bluesky

Bio
My research is at the intersection of Machine Learning, Natural Language Processing, and Neuroscience, with a focus on building computational models of language processing in the brain that can also improve natural language processing systems.
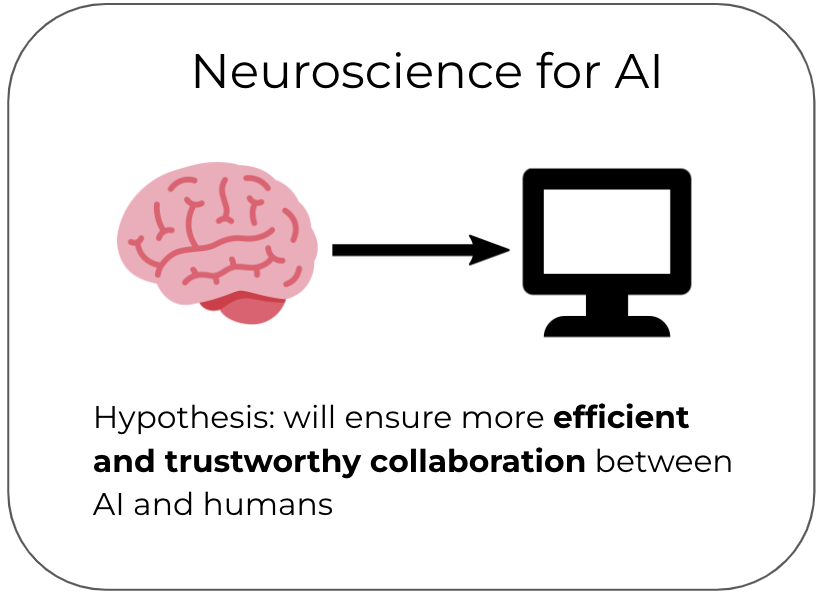
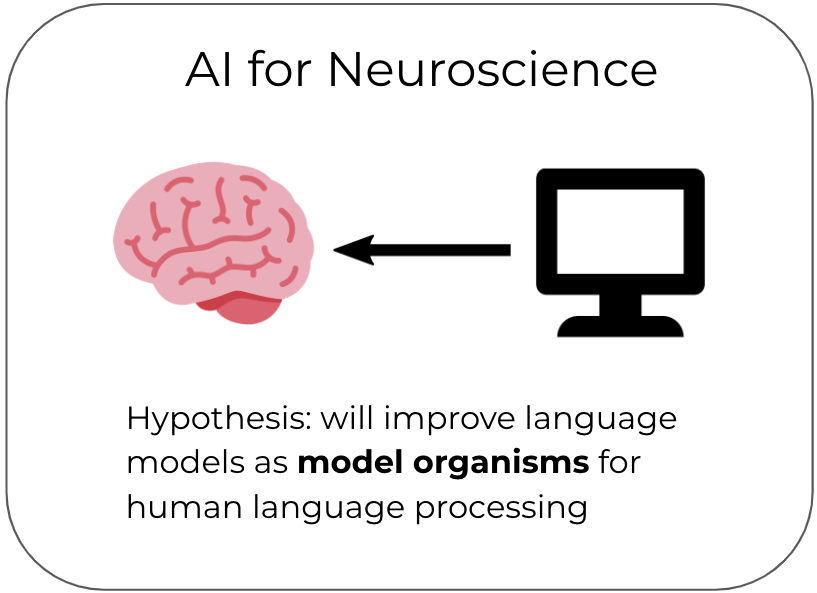
I lead the Bridging AI and Neuroscience group (BrAIN) at the Max Planck Institute for Software Systems. Our long-term goal is to improve alignment between AI systems and the human brain. We believe this improved alignment will benefit both AI and neuroscience in two main ways:
I also enjoy taking care of (helpful) bacteria and yeast and turning them into Bulgarian yogurt, kombucha, and sourdough bread from time to time. One of my favorite ways to relax is to bike or run along the many beautiful European paths with my husband Christoph Dann, who is always looking for sample efficient ways to reinforce my learning.
News
- Aug 25: 🎉 Work by PhD student Blerta Veseli on positional effects in LLMs accepted to COLM 2025!
- Jun 25: 🎉 Work by PhD student Omer Moussa on brain-like speech processing hierarchy in brain-tuned speech language models accepted to INTERSPEECH 2025!
- May 25: 🎉 Work by PhD student Camila Kolling on pointwise representational similarity accepted to TMLR!
- Apr 25: 🚨 Multiple open postdoc positions on topics related to AI, Computing, and Society, including Human Cognition and AI. Apply by May 13 via the new Max Planck Postdoc Program!
- Jan 25: 🎉 Work by PhD student Omer Moussa on brain-tuning speech language models accepted to ICLR 2025!
- Jan 25: 🎉 Work on helpfulness of hints in code and text-based program representations accepted to the International Conference on Software Engineering (ICSE)!
- Jan 25: 🎉 Work on high similarity between LLMs and human perception of boundaries between events published in Behavioral Research Methods!
- Dec 24: 🚨 Open postdoc position on effective human-AI collaboration, joint with Adish Singla and Sven Apel. Deadline to apply is Jan 31, 2025. More info here.
- Sept 24: 🎉 Work by PhD student Gabriele Merlin on reasons for alignment between brains and LLMs accepted to EMNLP 2024!
- July 24: Wrapping up preparations for CogSci 2024 in Rotterdam! Come join us!
Recent and Upcoming Talks
- Oct 27: Speaker at Workshop on "Large Language Models for Brain and Psychological Research" in Giessen, Germany
- Nov 18: Keynote at Neurocog 2025
- Dec 6: Keynote at NeurIPS 2025 Workshop "CogInterp: Interpreting Cognition in Deep Learning Models"